Details
-
Type:
 Bug
Bug
-
Status: Closed
-
Priority:
 Major
Major
-
Resolution: Fixed
-
Affects Version/s: 5.1.1
-
Fix Version/s: 6.3
-
Component/s: Core/Rendering
-
Labels:None
-
Environment:Linux, Java 1.7
Description
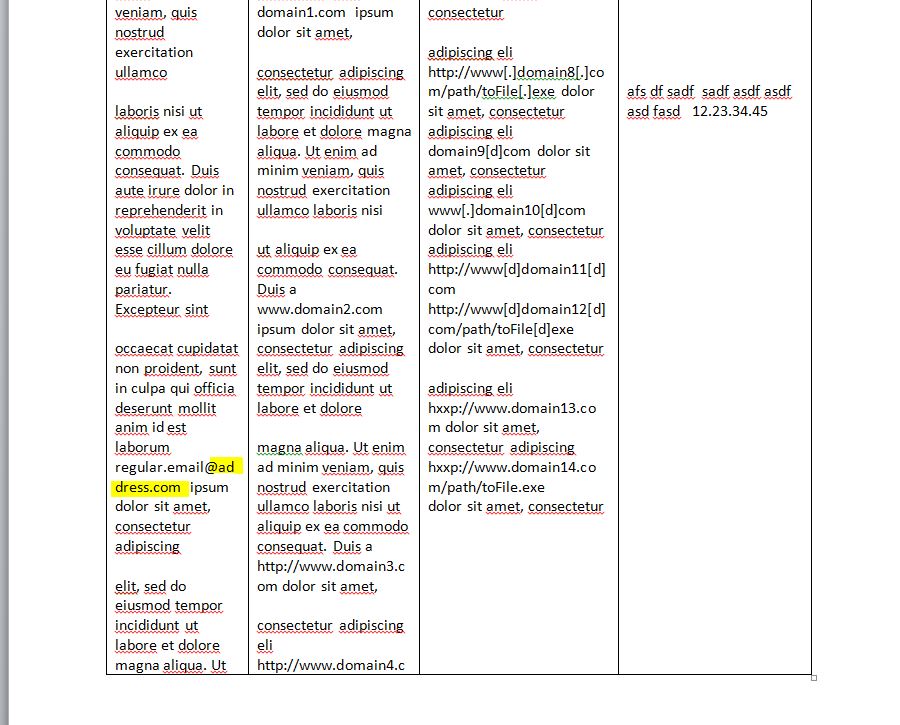
The text not able to be highlighted if it is aligned due to column in the document. For example if I search for "address.com", refer printscreen issue1.jpg (not highlighted) and issue2.jpg (highlighted)

Activity
- All
- Comments
- History
- Activity
- Remote Attachments
- Subversion