Details
-
Type:
 Bug
Bug
-
Status: Closed
-
Priority:
 Major
Major
-
Resolution: Fixed
-
Affects Version/s: 5.1.1
-
Fix Version/s: 6.3
-
Component/s: Core/Rendering
-
Labels:None
-
Environment:Linux, Java 1.7
Description

Activity
- All
- Comments
- History
- Activity
- Remote Attachments
- Subversion
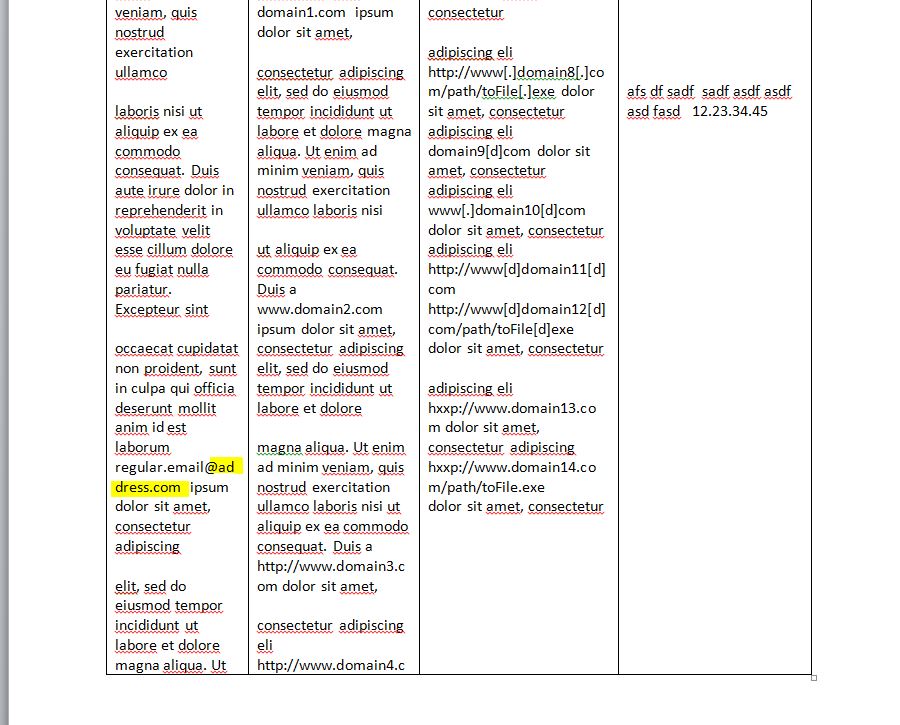
This is a tricky formatting issue. In PDF there is no definition of words, just the plotting of charactesr. Its up the the library to deduce words, lines, etc. Here is the post script for the text in question.
[code]
BT
1 0 0 1 72.024 216.62 Tm
[(regu)6(lar)4(.em)-4(ail)4(@a)3(d)] TJ
ET
Q
q
66.84 79.2 95.784 617.74 re
W* n
BT
1 0 0 1 72.024 203.18 Tm
[(d)3(ress.co)5(m)-4( )9( ipsu)6(m)-4( )] TJ
ET
[/code]
The easiest way to change the search behavior would be to alter the DocumentSearchControllerImpl.java. First you would need to alter searchPhraseParser to not break the search term by punctuation. Next you would need to change the loop structure of the searchHighlightPage() to avoid matching words but instead looking at individual GlyphText.
Hi,
Understand the challenges are eg: "abcdefg" 1 line become "abcde/nfg" if fit into the column format. and it is not possible to remove the /n as we may encounter scenario "abc/nefg" which is intended to be 2 lines "abc" and "efg".
would appreciate if you could give more detail guides or snippet sample on this suggestion , and I may work on it further to fix my need. Thanks.
Take a close look at DocumentSearchControllerImpl.java if you pass in "regular.email@address.com" as a search term our serachPhraseParser splits the email up into five search terms; regular, period, email@address, period and com. Acrobat has some special logic to try and detect email address and keeps them as one search term.
When we parse a PDF we try our best to order all the text to aid in text extraction as well as enable double click word selection and triple click line selection. The searchHighlightPage method of DocumentSearchControllerImpl uses the words as the basis for a search. For example in your test PDF if you search for 'ad' you'll get 25 results on the first page. But notice how we select the whole word "adipiscing" or "sadf". If you look at the search alogrithm we check to see if a term is contained in word and if so we flag the whole word to be drawn with a highlighted color.
Rather then to look at each word as a whole you could search by character, it's going to be a bit slower but should address the issue you are seeing. If you look at the LineText array for the lines in question you get:
line 36
regular, space, period, email@ad
line 37
dress, period , com, space, space, ipsum, space
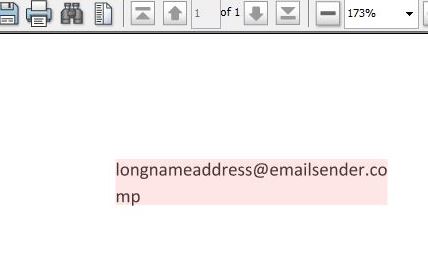
I had manage to highlight the individual GlyphText. So it is possible to highlight "address" out from "longnameaddress@emailsender.comp" correctly. However if the text spanned to nextline, the highlight goes wrong as it will highlight the whole 2 rows (attached picture2.jpg) , highlight using "comp" . Attached with my example file. (Breakline check.docx).
I am using approach as pseudo code below :
public ArrayList<LineText> searchHighlightPage(int pageIndex, int wordPadding) { foreach (LineText) forearch (WordText) if(isLastWordText of line) if(termTxt.contains(wordstring)) get next LineText (using index +1) manually and get first wordText from it. match if 1stWordText match (partial/fully) with termTxt loop each GlyphText from 1stWordText into new WordText(); // to highlight only the matched GlyphText and leave others. return new WordText() Add the new WordText() into searchPhraseHits set the word hit as highlight. end loop end loop }
I have check the GlyphText .getBounds(). when I tried the different highlight value to get bounds for "m"
glyphtext.getBounds() -- java.awt.geom.Rectangle2D$Float[x=72.0,y=742.4479,w=8.778,h=11.0], getX :0.0, getY :0.0
bounds for "p"
glyphtext.getBounds() -- java.awt.geom.Rectangle2D$Float[x=80.778,y=742.4479,w=5.7750015,h=11.0], getX :8.778, getY :0.0
and "comp"
termTxt : comp termChar : c, glyphtext.getCid : c , glyphtext.getBounds : java.awt.geom.Rectangle2D$Float[x=219.037,y=757.8899,w=4.6419983,h=11.0] , glyphtext.getX : 147.037,glyphtext.getY : 0.0, match :true termChar : o, glyphtext.getCid : o , glyphtext.getBounds : java.awt.geom.Rectangle2D$Float[x=223.679,y=757.8899,w=5.796997,h=11.0] , glyphtext.getX : 151.679,glyphtext.getY : 0.0, match :true termChar : m, glyphtext.getCid : m , glyphtext.getBounds : java.awt.geom.Rectangle2D$Float[x=72.0,y=742.4479,w=8.778,h=11.0] , glyphtext.getX : 0.0,glyphtext.getY : 0.0, match :true termChar : p, glyphtext.getCid : p , glyphtext.getBounds : java.awt.geom.Rectangle2D$Float[x=80.778,y=742.4479,w=5.7750015,h=11.0] , glyphtext.getX : 8.778,glyphtext.getY : 0.0, match :true
Where should I get the part to fix highlight correctly for this spanned line issue?
Hi,
We had manage to get the icepdf worked as desired. The method used was to extend and override my own code over and scan each GlyphText as suggested.
However there is a need to change the WordText.java
protected void addText(GlyphText sprite) {}
to public access.
I believe this can be benefit to others who may has requirement similar as mine someday too, so I was wondering if this can be a good suggestion to change it in the current icepdf core repository ?
It also will save us some pain for having to maintain a separate copy of source version on our own locally.
Marking as fixed.
Can you post the original file?