Details
-
Type:
 Bug
Bug
-
Status: Closed
-
Priority:
 Major
Major
-
Resolution: Fixed
-
Affects Version/s: 6.0.1, 6.0.2
-
Fix Version/s: 6.1.1
-
Component/s: Core/Parsing
-
Labels:None
-
Environment:All
-
Support Case References:Support Case #13657 - https://icesoft.my.salesforce.com/5007000001YEpXG
Description
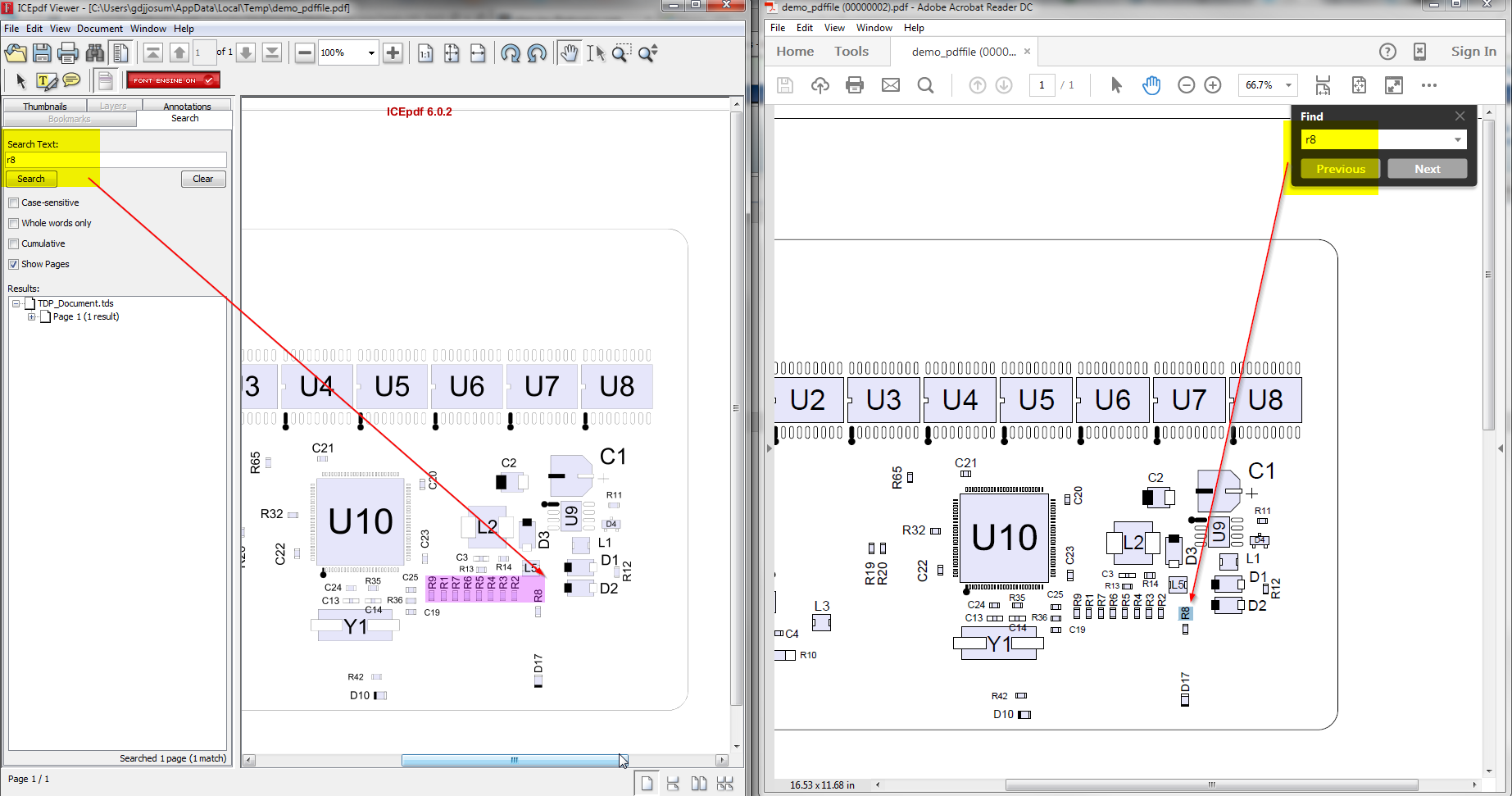
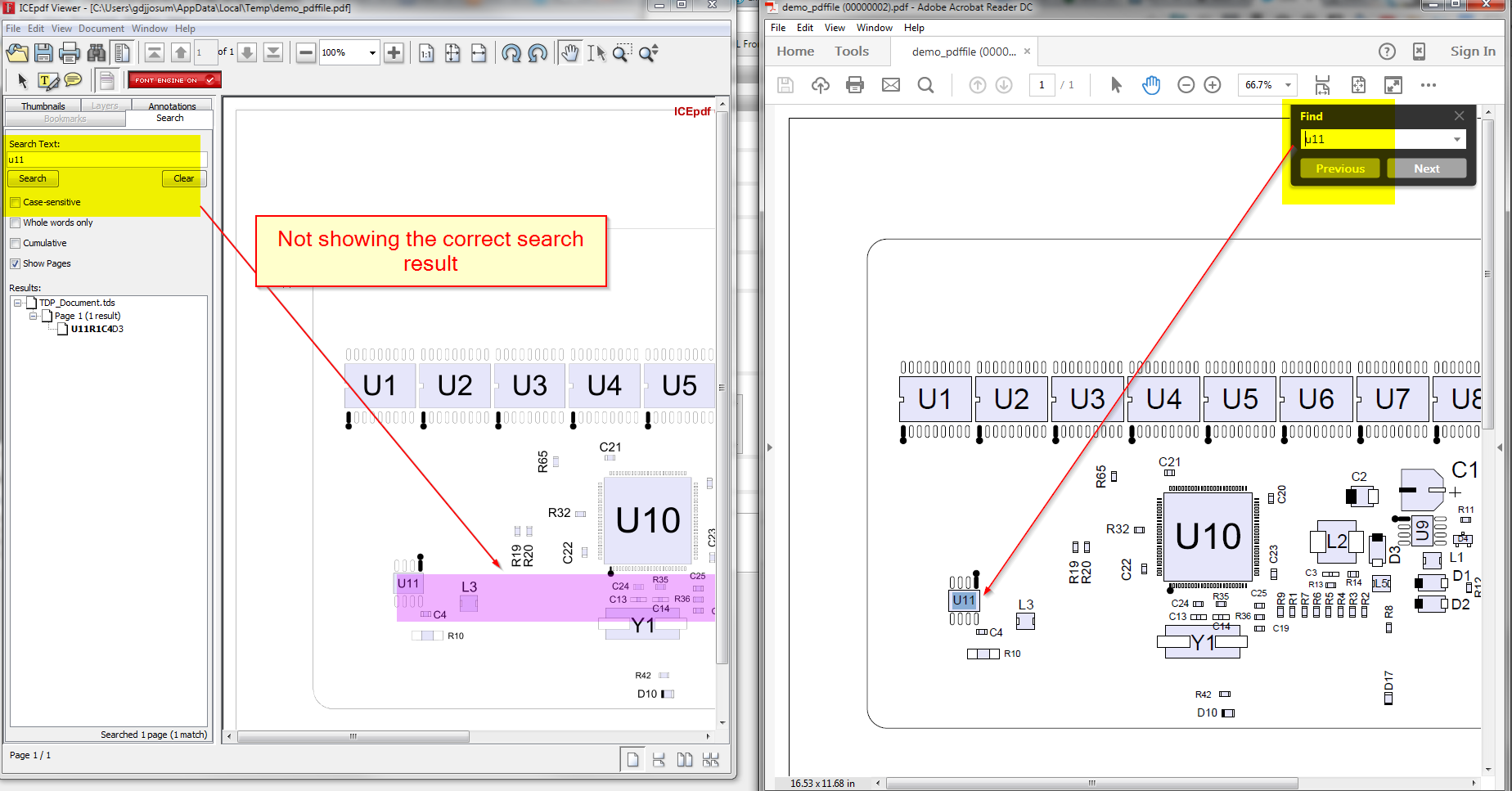
When searching for text with the provided PDF file in the ICEpdf Viewer, it highlights more area than just the specific text.
Activity
- All
- Comments
- History
- Activity
- Remote Attachments
- Subversion
This is a trick PDF but I think I have a solution that should have minimal impact on other users. As suspect the text layout change from horizontal to vertical introduce a couple corner cases when we try and find words. The first fix was to try and detect a change in orientation on the 'tm' change. The other corner case was related to our word space detection with the vertically oriented text. In such a case the x values with not change only the y value. This is the riskiest change and will require quite a bit of testing. But the PDF in question does behave correctly now with regards to search.
Show
 Patrick Corless
added a comment - This is a trick PDF but I think I have a solution that should have minimal impact on other users. As suspect the text layout change from horizontal to vertical introduce a couple corner cases when we try and find words. The first fix was to try and detect a change in orientation on the 'tm' change. The other corner case was related to our word space detection with the vertically oriented text. In such a case the x values with not change only the y value. This is the riskiest change and will require quite a bit of testing. But the PDF in question does behave correctly now with regards to search.
Patrick Corless
added a comment - This is a trick PDF but I think I have a solution that should have minimal impact on other users. As suspect the text layout change from horizontal to vertical introduce a couple corner cases when we try and find words. The first fix was to try and detect a change in orientation on the 'tm' change. The other corner case was related to our word space detection with the vertically oriented text. In such a case the x values with not change only the y value. This is the riskiest change and will require quite a bit of testing. But the PDF in question does behave correctly now with regards to search.
Marking a fixed.
Show
Patrick Corless
added a comment - Marking a fixed.
In this selection case the postscript looks as follows:
/F1 12.84 Tf 0 1 -1 0 0 0 Tm 240.1 -698.6 TD[(R)]TJ
9.12 0 TD[(3)]TJ
-9.12 14.4 TD[(R)]TJ
9.12 0 TD[(4)]TJ
-9.12 14.4 TD[(R)]TJ
9.12 0 TD[(5)]TJ
-9.12 14.52 TD[(R)]TJ
9.12 0 TD[(6)]TJ
-9.12 14.4 TD[(R)]TJ
9.12 0 TD[(7)]TJ
-9.12 -72.24 TD[(R)]TJ
9.12 0 TD[(2)]TJ
-25.2 -28.08 TD[(R)]TJ
9.12 0 TD[(8)]TJ
6.96 129.2 TD[(R)]TJ
9.12 0 TD[(9)]TJ
We have code that tries to property detect vertical writing but in this case I think the issue might be around new line detection as the letters are plotted out one by one and we need to look at Y to figure out if a word break is needed.